
TryOCR(识别看看)-OCR文字识别软件-TryOCR(识别看看)下载 v6.5绿色版
- 软件类型:图形软件
- 软件语言:简体中文
- 授权方式:免费软件
- 更新时间:2023-03-29
- 阅读次数:次
- 推荐星级:
- 运行环境:WinXP,Win7,Win10,Win11
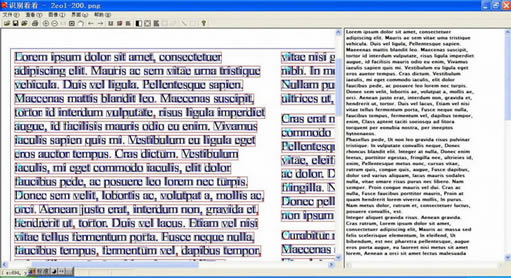
TryOCR识别看看是一款免费的OCR文字识别软件,它可以自动识别PDF或者图片中的文字内容并进行提取,不用手动摘录文字,支持简体中文和英文的识别,对于模糊、复杂的版面也能精准识别出来。
TryOCR软件简介
TryOCR(识别看看)是一款简单高效的OCR文字识别软件,可以自动识别、图片中的文字,并将其抄录下来,方便进行编辑。TryOCR拥有较高的识别率和识别速度,在面对大量图像或文档时将为你节省不少力气。
TryOCR软件简单易用,支持文档识别、框选识别、多行识别三种模式,它还有额外的文字识辅助别功能:包括二值化、旋转校正、版面分析、边框去除、噪声去除等,而且还是免费软件,避免了版权风险。
TryOCR软件功能
文档识别:像书集,报纸,名片等含有文字的图片,都可以称之为文档,都可以用这个工具按钮来进行识别。
框选识别:从文档中框选出一个文字区域进行识别,就叫做“框选识别”,为了使识别率更高,速度更快,您最好不要将非文字区域框选进来
简单多行文档识别:如果您的文档只存在一列文字,没有复杂的背景,不含其它插图等非文字信息,那么您可以选该工具进行识别,它将使这种图片的识别结果更准确,速度更快。
二值化图片:将彩色的或者灰色图片变成只有黑白两色的图片。
文档倾斜较正:由于一般用户拍摄文档图片比较随意,造成文档中的文字行存在一定的倾斜,为了识别,我们可以先将其进行较正。
文档版面分析:我们对整个文档的识别过程中,需要对文档先切割成一行行文字,这一过程就叫做版面分析。
边框去除:像书集,报纸,名片,这种图片,往往存在一个不含文字的外围区域,我们为了提高识别速度,将事先把这一区域去除掉。
噪声去除:像书集,报纸,名片,这种图片,由于光照的不均匀,背景插图等原因,经过二值化处理后,会产生一些大大小小的非文字区域,将这些区域去除掉就叫做噪声去除。
TryOCR安装说明
下载TryOCR,解压压缩包,双击.exe文件,选择语言,
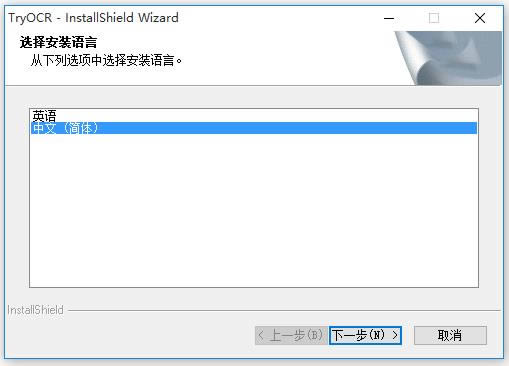
根据向导提示操作,

阅读许可协议,选择接受,进行下一步,

选择软件安装类型,进行下一步,
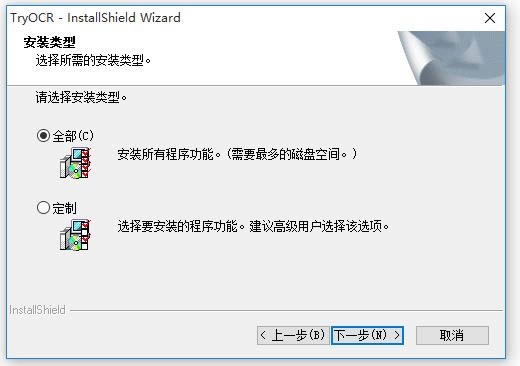
准备就绪,点击【安装】,
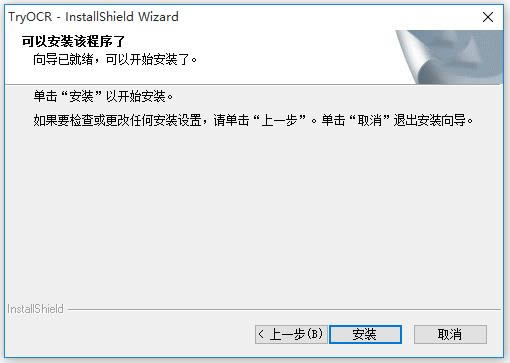
开始安装软件,耐心等待即可。


TryOCR使用方法
答:使用很简单,打开菜单“文件(F)”==>“打开(O)”==>选择图片路径,选择图片==>“图像(I)”==>“文档识别”,如果想了解得更详细一些,您可以打开帮助文档看看(打开软件后按F1键,或者打开菜单"帮助(H)"==>"帮助")